
УДК 004
ВЫДЕЛЕНИЕ КЛЮЧЕВОЙ ИНФОРМАЦИИ ПРИ СКРЕПИНГЕ САЙТОВ НА РУССКОМ ЯЗЫКЕ С ИСПОЛЬЗОВАНИЕМ GPT3 И ФРЕЙМВОРКА БОЛЬШИХ ДАННЫХ APACHE SPARK
№39,
Технические науки
Качанов Юрий Александрович
Ключевые слова: НЕЙРОННЫЕ СЕТИ; БОЛЬШИЕ ДАННЫЕ; ОБОБЩЕНИЕ ТЕКСТА; ВЕБ-САЙТЫ; NEURAL NETWORKS; BIG DATA; TEXT SUMMARIZATION; WEBSITES.
Введение
Разработка программной системы для выделение ключевой информации во время обработки веб-сайтов в данное время имеет высокую значимость, так как данный подход позволяет получать пользователю краткую и полную информацию из различных областей таких как политика, экономика, спорт и др. На сегодняшний день создание такой системы является довольно перспективным направлением, так как данная программная система позволит значительно сократить время человека на получение новой информации из информационных веб-сайтов.
Нейронная сеть GPT3
GPT-3 (Generative Pre-trained Transformer 3) — это языковая модель, созданная OpenAI, исследовательской лабораторией искусственного интеллекта в Сан-Франциско. Модель глубокого обучения, которая содержит 175 миллиардов параметров способна создавать человекоподобный текст и была обучена на больших текстовых наборах данных с сотнями миллиардов слов [1].
GPT-3 по сути является моделью-трансформером. Модели-трансформеры — это модели глубокого обучения «последовательность за последовательностью», которые могут создавать последовательность текста на основе входной последовательности.
Для дообучения данной нейронной сети будет использоваться датасет собранный с сайта www.gazeta.ru. Датасет для обучения содержит 60964 записи с новостями за период с июня 2010 по декабрь 2019 включительно. Проверочный набор данных содержит 6369 записей и 6793 для тестового набора данных [2].
Использование технологии больших данных Apache Spark
Согласно Apache, Spark — это быстрый и универсальный механизм для крупномасштабной обработки данных. Spark может распределять обработку данных между огромным кластером компьютеров, беря задачу анализа данных, которая слишком велика для выполнения на одной машине, и разделяя ее между несколькими машинами, что приводит к увеличению скорости работы такого приложения [3].
Spark состоит из множества компонентов. Используя Spark Core, который отвечает за управление памятью, восстановлением после отказа, распределением задач на кластере и взаимодействием с различными системами хранения данными. Spark Core позволяет работать с объектами типа RDD (устойчивый распределенный набор данных), которые хранятся в оперативной памяти, что позволяет их обрабатывать параллельно. На рисунке 1 представлены основные модули фреймворка Apache Spark [4].

Рисунок 1 – Основные модули фреймворка Apache Spark
Apache Spark также включает в себя библиотеки для применения методов машинного обучения и анализа графов к данным в любом масштабе. Spark MLlib включает в себя платформу для создания конвейеров машинного обучения, позволяющую легко реализовать извлечение признаков, выборку и преобразование в любом структурированном наборе данных. MLlib поставляется с распределенными реализациями алгоритмов кластеризации и классификации, таких как кластеризация k-средних и случайные леса, которые можно легко переключать в пользовательские конвейеры и из них. Специалисты по данным могут обучать модели в Apache Spark с использованием R или Python, сохранять их с помощью MLlib, а затем импортировать в конвейер на основе Java или Scala для дальнейшего использования.
Ниже представлен алгоритм работы приложения, который вначале загружает дообученную нейронную сеть, затем выполняет в распределенном режиме скрепинг сайтов, то есть создает множество потоков, которые загружают веб-сайты, получают их текст и затем его обрабатывают. После этого загруженные тексты будут подаваться на вход нейронной сети, которая будет выдавать их краткое содержание, которое затем будет выдаваться пользователю.
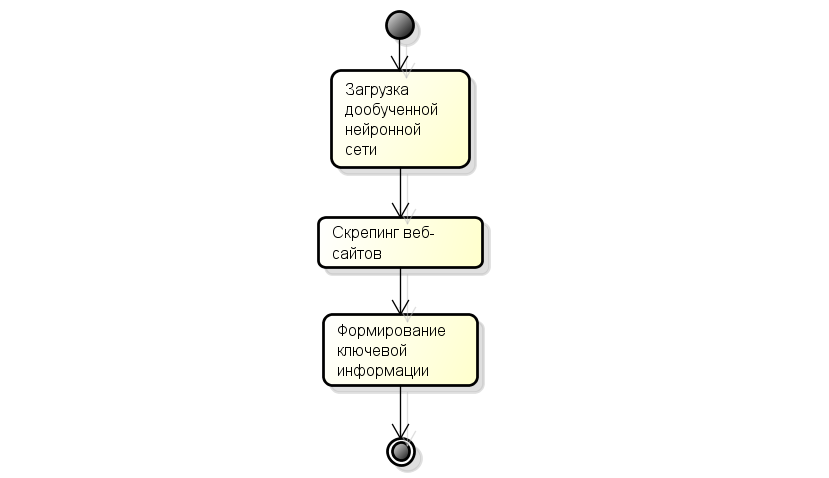
Рисунок 2 – Алгоритм работы приложения
Список литературы
- What is GPT-3 and why is it so powerful? | Towards Data Science | Towards Data ScienceURL: https://towardsdatascience.com/what-is-gpt-3-and-why-is-it-so-powerful-21ea1ba59811 (Дата обращения 30.08.2022).
- Gazeta Summaries | Kaggle URL: https://www.kaggle.com/datasets/phoenix120/gazeta-summaries
- Frank, K. Frank Kane’s Taming Big Data with Apache Spark and Python / Packt Publishing. Birmingham, 2017. -289 c.
- What is Apache Spark? The big data platform that crushed Hadoop | InfoWorld URL: https://www.infoworld.com/article/3236869/what-is-apache-spark-the-big-data-platform-that-crushed-hadoop.html (Дата обращения 31.08.2022).