
УДК 004.852
АВТОМАТИЧЕСКИЙ ПЕРЕВОД ПИКТОГРАММНЫХ СООБЩЕНИЙ В СВЯЗНЫЙ ТЕКСТ НА РУССКОМ ЯЗЫКЕ С ПОМОЩЬЮ ТЕХНОЛОГИЙ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
№34,
Технические науки
Матюшечкин Дмитрий Сергеевич
Ключевые слова: ВСПОМОГАТЕЛЬНЫЕ ТЕХНОЛОГИИ; МАШИННОЕ ОБУЧЕНИЕ; НЕЙРОННЫЕ СЕТИ; ПИКТОГРАММНЫЕ СООБЩЕНИЯ; РЕЧЕВЫЕ НАРУШЕНИЯ; ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА; ГЕНЕРАЦИЯ ТЕКСТА НА РУССКОМ ЯЗЫКЕ; ASSISTIVE TECHNOLOGY; MACHINE LEARNING; NEURAL NETWORKS; PICTOGRAM MESSAGES; SPEECH DISORDERS; NATURAL LANGUAGE PROCESSING; RUSSIAN TEXT GENERATION.
Разработка программного средства для перевода пиктограммных сообщений в связный текст на русском языке направлена на решение проблем коммуникации людей с речевыми нарушениями, которые не могут в полной мере использовать вербальную речь и испытывают проблемы с социальной адаптацией, развитием и самообслуживанием. На сегодняшний день наиболее эффективным средством альтернативной коммуникации являются пиктограммные сообщения-карточки с изображениями, заменяющими слова, с помощью которых составляются сообщения и производится обмен информацией [1]. На данный момент существуют различные программные средства, которые облегчают работу с пиктограммами, однако ни одно из них не позволяет переводить составленные из пиктограмм сообщения в связный текст, из-за чего коммуницирующие стороны должны владеть навыками работы с пиктограммами или прибегать к помощи специалиста для перевода сообщений.
Машинное обучение на параллельных текстовых корпусах.
В процессе исследования задачи автоматического перевода пиктограммных сообщений в связный текст было выяснено, что одним из наиболее эффективных методов решения задачи перевода является машинное обучение на параллельных текстовых корпусах.
Нейронный машинный перевод рассматривает условный язык для моделирования перевода, описывая вероятность результирующего предложения на основе входного предложения. В основе данного подхода лежит архитектура, включающая кодер, декодер и сети «внимания». На вход модели нейронной сети подается векторное представление слов входного предложения, которые подаются в рекуррентную нейронную сеть (RNN). При достижении конца входной последовательности, происходит инициализация результирующей RNN. Далее, в течение нескольких условных шагов, производится предсказание каждого слова результирующего предложения при переводе [2].
Подготовка данных для обучения нейронной сети.
В силу того, что в задаче перевода пиктограммных сообщений в связный текст исходный язык для перевода является специфичным, был разработан новый метод сбора данных для обучения нейронной сети.
Так как в качестве исходного языка для перевода является последовательность пиктограмм, а не текст на естественном языке, необходимо использовать исходную текстовую интерпретацию пиктограммного сообщения (последовательность инфинитивных форм). Таким образом, текст исходного языка должен быть представлен набором последовательностей лемм, а параллельный ему текст на результирующем языке должен состоять из предложений, где данные леммы согласованы.
Для генерации такой пары параллельных текстовых корпусов был разработан новый комплекс алгоритмов сбора и подготовки данных для обучения нейронной сети.
В основе первого алгоритма лежит рекурсивный обход гипертекста и сохранение текстового содержимого каждого узла. Обход гипертекста производился по содержимому интернет-ресурса «Википедия» с дальнейшей обработкой полученных текстов. Обработка заключается в очистке текста от разметки HTML, получения только контентных частей веб-страниц и разбиения полученных текстов на предложения. После рекурсивного обхода 50 тысяч узлов гипертекста был собран корпус из 1 миллиона предложений.
Следующим алгоритмом является алгоритм формирования параллельного текстового корпуса на основании собранных предложений. Параллельный текстовый корпус формируется в процессе лемматизации каждого слова предложения, что позволяет получить новый корпус последовательностей лемм, соответствующий собранным предложениям. Примеры подготовленных предложений для параллельных текстовых корпусов представлены на рисунке 1.
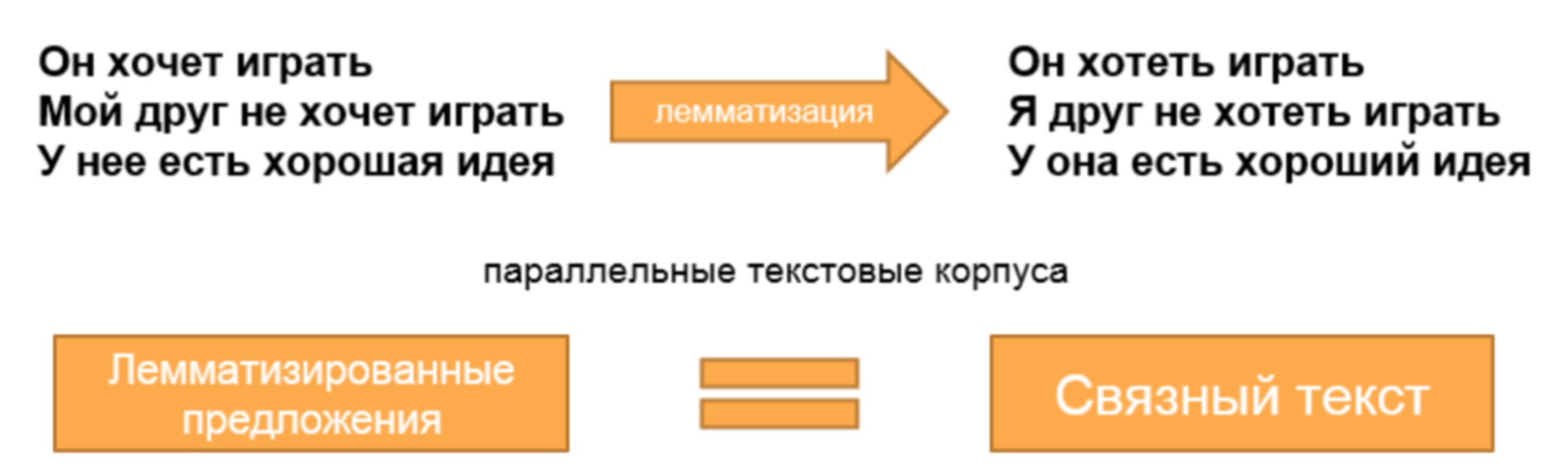
Рисунок 1 – Примеры подготовленных предложений для параллельных текстовых корпусов
Для лемматизации каждого слова в согласованных предложениях был использован инструмент “Яндекс-стеммер” для языка программирования “Python”.
Таким образом, для обучения нейронной сети были получены наборы текстов: последовательности лемм и их согласованные варианты в виде предложений. Поэтому исходным языком можно считать последовательность лемм, а переводом – предложение, составленное из них. Например, последовательность лемм «я хотеть спать» и перевод «я хочу спать».
Результаты обучения нейронной сети.
Полученные параллельные тексты дают возможность обучить нейронную сеть, с помощью которой можно производить согласования лемм в предложения. Однако, в силу того, что последовательность лемм образуется путем составления фраз из пиктограмм (символических изображений), то в таких последовательностях часто опускаются предлоги или путается порядок изображений. Например для составления фразы «я хожу в школу» используются только пиктограммы «я», «ходить» и «школа», а правильный предлог при переводе должен быть добавлен нейронной сетью. Поэтому возникла необходимость разработать комплект алгоритмов для добавления статистического «шума» в корпусе с набором лемм. Данные алгоритмы производят удаление предлогов с заданной частотой, случайно переставляют леммы местами и дублируют некоторые последовательности лемм.
После перечисленных способов обработки производилось обучение модели нейронной сети и производилась ее оценка.
Для создания нейронной сети был выбран специальный фреймворк “OpenNMT-py” для языка “Python”, который способен на основе двух параллельных текстов создать модель перевода и использовать ее. Помимо обучающих корпусов, на вход “OpenNMT-py” [3] требуются дополнительно два параллельных корпуса, чтобы осуществлять валидацию данных по мере обучения и оценивать точность перевода модели в промежуточных состояниях обучения. В связи с этим, подготовленные корпуса были раз-делены таким образом, чтобы на вход “OpenNMT-py” было передано 800 тысяч последовательностей лемм и их параллельных переводов для обучения нейронной сети, а 200 тысяч для ее валидации.
Одним из важных преимуществ фреймворка “OpenNMT-py” является то, что для ускорения процесса обучения нейронной сети можно использовать технологию параллельных вычислений “CUDA”, что значительно сократило время обучения сети.
Обучение сети проводилось в 30 эпох, на каждой из которых оценивались параметры точности перевода (accuracy) и “недоумения” (perplexity). На каждой эпохе параметр accuracy увеличивался, а perplexity уменьшался, что говорит о повышении качества сети в процессе обучения и отсутствии негативного явления пере-обучения сети.
В результате обучения была создана новая рекуррентная нейронная сеть, способная преобразовывать последовательности лемм в согласованные предложения на русском языке.
Применение разработанной нейронной сети.
На основе полученной нейронной сети был разработан прототип нового веб-сервиса, к которому можно обращаться через браузер и использовать функции перевода.
Для перевода пиктограммных сообщений в текстовые на русском языке в интерфейсе веб-сервиса выводится группированный по темам список пиктограмм, из которых можно составлять пиктограммные сообщения. Макет экранной формы разработанного веб-сервиса представлен на рисунке 2.
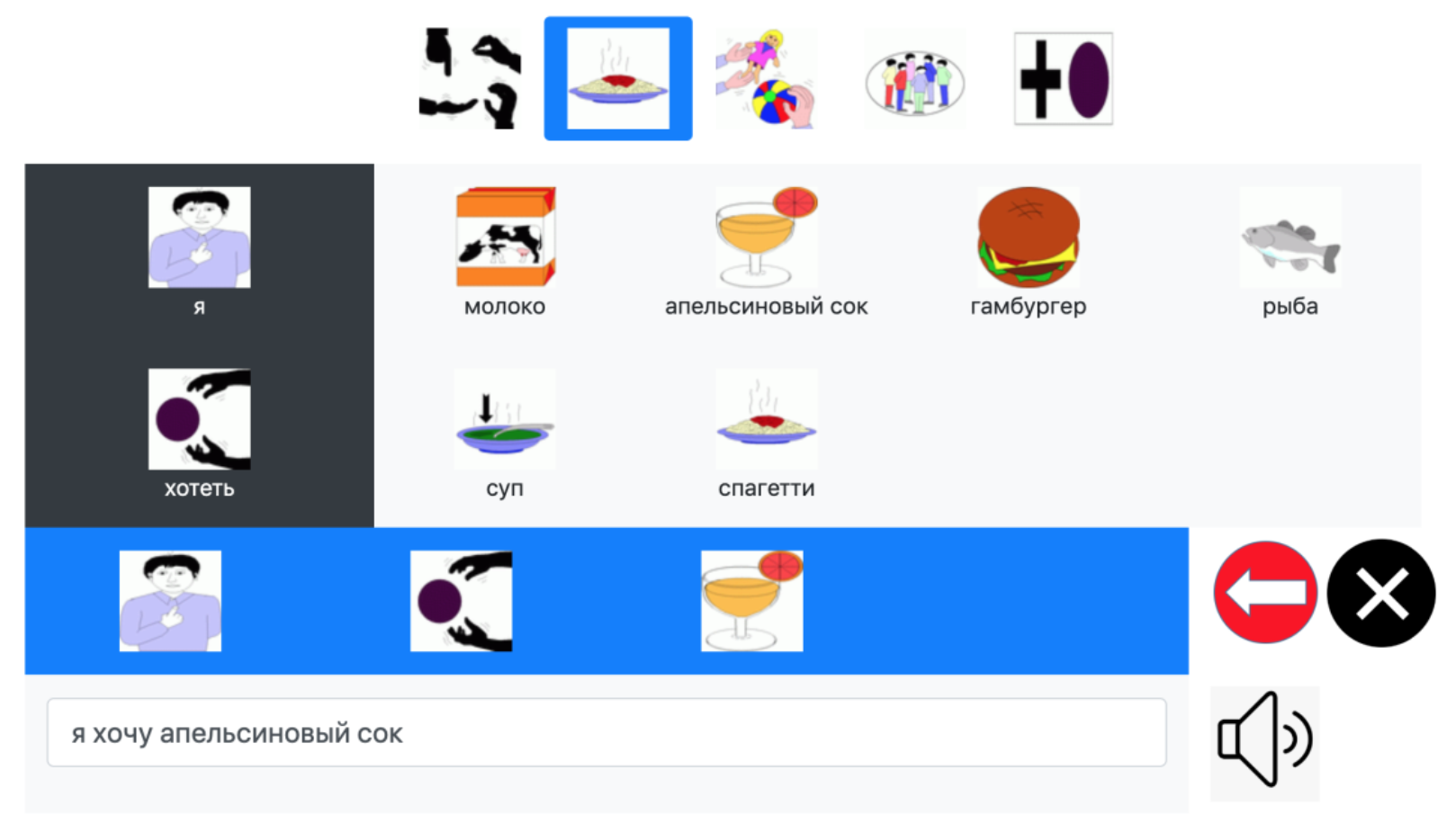
Рисунок 2 – Макет экранной формы разработанного веб-сервиса.
Для внесения коррективов в составляемое пиктограммное сообщение в интерфейсе добавлены кнопки для удаления последней добавленной пиктограммы и удаления всех добавленных пиктограмм.
Тестирование разработанного веб-сервиса на различных этапах разработки проводилось с участием конечных пользователей в детском реабилитационном центре «Надежда» в г. Волжский. Также специалисты реабилитационного центра оказали помощь в получении обратной связи с пользователями и исследовании особенностей предметной области разработки.
Список литературы
- Смирнова, И.А. Неартикулируемые средства общения и методика их использования в работе по формированию коммуникативности у неговорящих детей / И.А. Смирнова // Логопедическая диагностика, коррекция и профилактика нарушения речи у детей с ДЦП. Алалия, дизартрия, ОНР. – СПб.: Речь. – 2004. – с. 206-226.
- О машинном переводе // Документация API переводчика «Яндекс». Режим доступа: https://yandex.ru/dev/translate/doc/dg/concepts/how-works-machine-translation.html. (Дата обращения 28.12.2021).
- OpenNMT-py URL: http://opennmt.net/OpenNMT-py/ (дата обращения: 05.12.2021).
- L. Sevens, V. Vandeghinste, I. Schuurman, and F. Van Eynde, “Natural Language Generation from Pictographs,” in ENLG 2015 – Proceedings of the 15th European Workshop on Natural Language Generation, 2015.