
УДК 81’32+81’42
КЛАССИФИКАЦИЯ ЛИНГВИСТИЧЕСКИХ КОРПУСОВ
№31,
Филологические науки
Манукянц Сурен Валерьевич
Ключевые слова: ЛИНГВИСТИЧЕСКИЙ КОРПУС; КОРПУСНАЯ ЛИНГВИСТИКА; КЛАССИФИКАЦИЯ КОРПУСОВ; LINGUISTIC CORPUS; CORPUS LINGUISTICS; CORPUS CLASSIFICATION.
Корпусная лингвистика является сравнительно молодым направлением, которое, тем не менее, активно развивается. Она, как и компьютерная лингвистика, возникла на стыке информатики и математической лингвистики. Предметом корпусной лингвистики являются теоретические основы и практические механизмы создания и использования представительных массивов языковых данных (лингвистических корпусов), предназначенных для лингвистических исследований в интересах широкого круга пользователей [1, с. 6].
Многообразие исследовательских и прикладных задач обуславливает существование корпусов различных типов. Сравнительный анализ научной литературы [1; 2; 3; 4] позволил синтезировать единую классификацию (см. табл. 1).
Таблица 1 – Критерии классификации и типология корпусов
| Критерии классификации | Виды корпусов |
| Тип языковых данных | Устные / Письменные / Смешанные |
| Формат представления данных | Мономодальные / Мультимодальные (мультимедийные) |
| Объем и полнота данных | Общие (представительные, национальные) / Для специальных целей: мониторинговые, иллюстративные |
| Число представленных языков | Одноязычные / Двуязычные / Многоязычные |
| Число языков в одном тексте (для дву- и многоязычных корпусов) | Параллельные[*1] / Смешанные |
| Выравнивание (alignment) текстов на разных языках (для дву- и многоязычных корпусов) | Соизмеримые или параллельные / Несоизмеримые или непараллельные |
| Наличие единых принципов отбора языкового материала | Сопоставимые (comparable) / Несопоставимые |
| Представленность языкового материала | Полнотекстовый / Фрагментированный (в т.ч. корпуса n-грамм и конкордансы) |
| Временной период, к которому относятся собранные языковые данные | Синхронные / Диахронные |
| Наличие разметки | Размеченные (аннотированные) / Неразмеченные (неаннотированные) |
| Тип разметки (для размеченных корпусов) | Метатекстовая разметка / Лингвистическая разметка (морфологическая, синтаксическая, семантическая) / Экстралингвистическая разметка |
| Доступность | Свободно доступные / Частично доступные / Закрытые (коммерческие) |
| Уровень лингвистической компетентности авторов | Корпуса аутентичных текстов / Корпуса текстов, созданных изучающими второй/иностранный язык / Корпуса детской речи |
[*1] Автор этой классификации, М.В. Копотев, использует название «параллельные» дважды: в данном случае и для обозначения корпуса, в котором произведено выравнивание, т.е. установлено сопоставление между аналогичными фрагментами текстов на разных языках.
Первым критерием является тип языковых данных, который позволяет разделить корпуса на устные (отражение только устной речи), письменные (отражение только письменной речи) и смешанные (наличие в языковом массиве корпуса речи обоих типов).
Первоначально даже устные корпуса представляли речь в письменном формате, т.е. в виде транскриптов. Современные технологии позволяют включать в корпус не только транскрипты, но и аудио-, и видеофрагменты, на которых зафиксирована продукция соответствующих текстов. Соответственно, формат представления корпусных данных является вторым критерием классификации. Корпуса, которые содержат данные только в текстовом виде, называются мономодальными, корпуса, в которых наряду с речью содержатся аудио и / или видеозаписи коммуникативных актов, – мультимодальными или мультимедийными. Последние стали активно развиваться в последнее время, хотя это развитие сдерживается требовательностью этих корпусов к ресурсам для их хранения и обработки (особенно если в корпусе используются видеоматериалы).
Важным критерием классификации является количество языков, которые отражает корпус. Соответственно, различаются одноязычные, двуязычные и многоязычные корпуса. Для дву- и многоязычных корпусов существуют 2 дополнительных критерия дальнейшей классификации.
Первый из них – количество языков, применяемых в одном тексте – позволяет выделить параллельные корпуса (в каждом тексте используется только один из языков, представленных в корпусе) и смешанные (в каждом тексте может использоваться более одного языка).
Второй критерий – взаимное выравнивание текстов (alignment) на разных языках – позволяет выделить параллельные (соизмеримые) и непараллельные (несоизмеримые). В первом случае речь идёт о том, что один и тот же языковой материал представлен в корпусе одновременно на разных языках и между аналогичными текстами разных языков установлено соответствие, которое позволяет сразу увидеть, как один и тот же фрагмент текста выглядит на разных языках. Во втором случае такого соответствия нет. Пример отображения результатов поискового запроса в параллельном корпусе показан на рис. 1. Цифрами на рисунке обозначены: 1 – фрагмент на русском языке (оригинал); 2 – фрагмент на армянском языке (перевод); 3 – фрагмент на армянском языке в транскрипции латиницей (перевод).
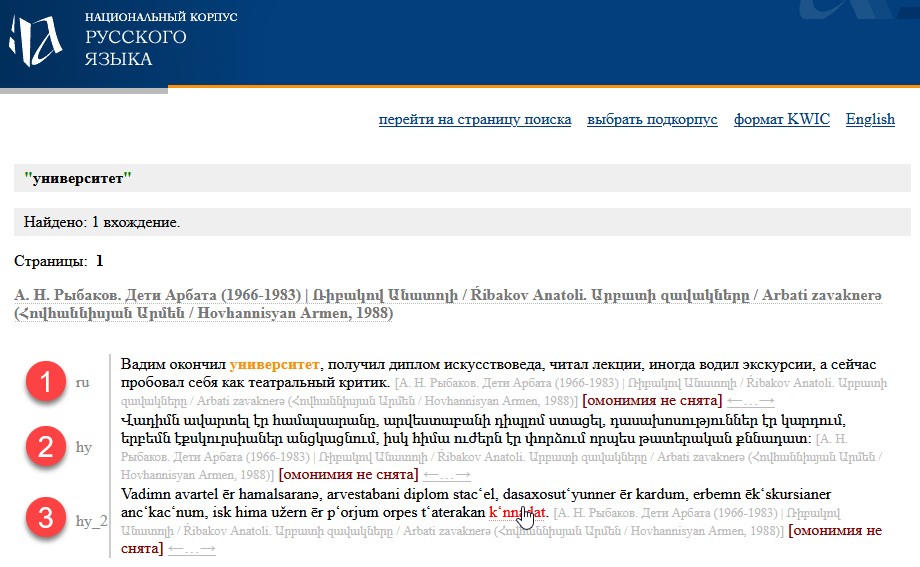
Рис. 1. Результаты поискового запроса «университет» в армянском параллельном подкорпусе НКРЯ [4]
С отображением языкового материала на разных языках связана и ещё одна классификация, которая подразделяет корпуса на сопоставимые (comparable) и несопоставимые. Критерием здесь является наличие единых принципов отбора языкового материала. То есть исследования одних и тех же лингвистических явлений на базе сопоставимых корпусов позволяют получать сравнимые между собой результаты, что позволяет проводить сравнительные исследования.
По охвату временного периода, к которому относятся представляемые языковые данные, можно выделить синхронные и диахронные корпуса. В первом случае корпус фиксирует состояние языка на определённый момент времени, а во втором данные собираются за какой-то значительный промежуток времени, что позволяет отслеживать динамику изменений, происходящих в языке.
Следующий критерий классификации – полнота текстов, включённых в корпус. Если в корпус входят тексты целиком, то он называется полнотекстовым, если только фрагменты – фрагментированным. Примерами фрагментированных корпусов являются конкордансы и корпуса n-грамм.
Ранее мы достаточно много внимания уделили такой черте лингвистического корпуса как разметка. Её наличие и тип также являются основаниями для классификации. По наличию разметки (аннотации) корпуса делятся на размеченные (аннотированные) и неразмеченные (неаннотированные). В свою очередь размеченные корпуса можно классифицировать по типу имеющейся разметки, которую можно обобщённо разделить на метатекстовую, лингвистическую и экстралингвистическую.
Одна из самых подробных схем метаразметки представлена в Национальном корпусе русского языка (она называется паспорт текста).
- (Для всех текстов)
- Автор текста и сведения о нем
- Название текста
- Время создания текста
- Объем текста
II.1. Художественные тексты
- Жанр текста
- Тип текста
- Хронотоп текста
II.2. Нехудожественные тексты
- Сфера функционирования текста
- Тип текста
- Тематика текста [4]
Уже эта информация позволяет проводить исследования по стилистике, истории, региональным вариантам языка. Отметим, что фактически подавляющее большинство современных корпусов в той или иной мере обладают метатекстовой разметкой, т.к. без неё очень сложно оценивать применимость результатов исследований, полученных на базе корпуса. Пример минимальной метатекстовой разметки можно увидеть на рис. 2.

Рис. 2. Метатекстовая разметка на примере корпуса «Весёлые истории из жизни» [6]
Значительно больший интерес для лингвистов представляют корпуса, которые наряду с метатекстовой разметкой содержат языковую (лингвистическую) разметку. Степень её проработанности значительно отличается от корпуса к корпусу, однако, как отмечает М. Копотев, почти все корпуса содержат сведения о начальной форме, точнее лемме. Многие корпуса предлагают частичное или полное морфологическое аннотирование; редкие – синтаксический разбор; почти нет таких, которые содержат фонетическое и просодическое аннотирование [3, с. 25-26]. Принципы разметки, как правило, совпадают с разработанным в лингвистических теориях делением языковой системы на уровни: фонетическая, морфологическая, синтаксическая, семантическая и т. д.
У мультимодальных корпусов возможен ещё один тип разметки – экстралингвистическая. Стоит отметить, что при разметке мультимодального корпуса на первом этапе происходит преобразование звучащей речи в письменную (транскрибирование), а затем к этой разметке добавляется экстралингвистическая разметка. На рис. 3 показано 2 варианта разметки аудиофрагмента в корпусе «Рассказы о сновидениях».
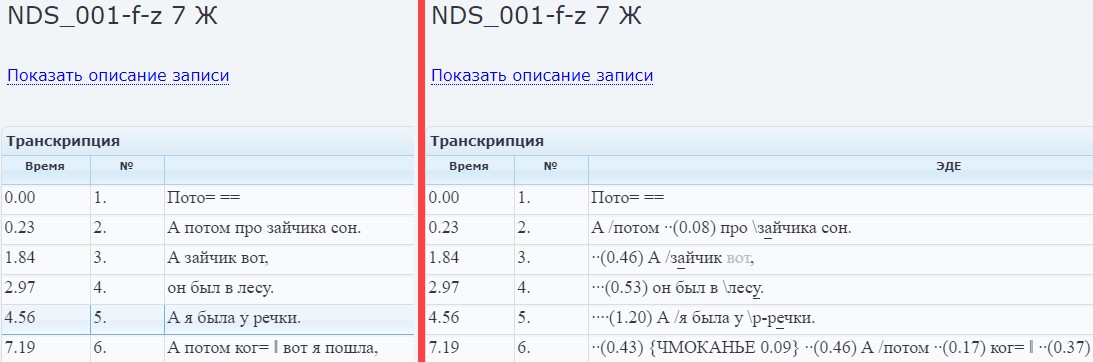
Рис. 3. Экстралингвистическая разметка корпуса «Рассказы о сновидениях» [4]
Слева на рис. 3 виден базовый вариант транскрипции, который содержит в себе только произносимый рассказчиком текст. Это вариант в указанном корпусе называется «Минимальная». Справа показана «Полная» транскрипция, которая уже содержит в себе экстралингвистическую информацию о паузах, движении тона, посторонних звуках и т.д.
Показанные выше примеры взяты из корпусов со свободным доступом, т.е. они доступны для использования любому пользователю интернета. Соответственно, исследователи выделают ещё один критерий классификации – доступность. Помимо свободно доступных корпусов, существуют также корпуса с ограниченным доступом, когда, например, всем желающим доступно только ограниченное количество результатов поисковой выдачи или ограниченный набор исследовательских инструментов, а также закрытые корпуса, доступ к которым предоставляется только на коммерческой основе или вовсе не предоставляется никому, кроме его разработчиков.
Нередко в исследованиях можно встретить т.н. Learner corpora, которые составляются из текстов, созданных людьми, изучающими иностранный язык. Фактически это корпуса текстов на втором или иностранном языке (чаще всего на английском). В ходе анализа существующей научной литературы мы не смогли встретить критерия, который позволял бы выделить такие корпуса, поэтому предлагаем ввести дополнительный критерий – уровень лингвистической компетентности авторов материала. Соответственно, в первом приближении мы сможем выделить корпуса языкового материала, созданного носителями языка (их подавляющее большинство), и корпуса языкового материала, созданного изучающими язык. Этот критерий позволяет нам также включить в данную классификацию корпуса детской речи (Child-Language Corpora), которые фиксируют реальное языковое поведение детей, осваивающих родной язык [4, с. 305].
Как было отмечено в начале статьи, лингвистический корпус возник в арсенале инструментов лингвиста сравнительно недавно. Это приводит к недостатку навыков работы с ним и, следовательно, ошибкам в применении. На наш взгляд, уточнение критериев классификации лингвистических корпусов позволяет исследователям упростить выбор корпуса, который соответствует тем целям и задачам, которые возникают в рамках конкретных исследований.
Список литературы
- Захаров В.П., Богданова С.Ю. Корпусная лингвистика: Учебник для студентов направления «Лингвистика». 2-е изд., перераб. и дополн. – СПб.: СПбГУ. РИО. Филологический факультет, 2013. – 148 с.
- Козлова Н. В. Лингвистические корпуса: определение основных понятий и типология // Вестник НГУ. Серия: Лингвистика и межкультурная коммуникация. – 2013. – №1. – С. 79-87.
- Копотев М. Введение в корпусную лингвистику: Учебное пособие для студентов филологических и лингвистических специальностей университетов. – Прага: Animedia, 2014. – 230 с.
- A Practical Handbook of Corpus Linguistics [edited by M. Paquot, S. Gries]. Springer International Publishing, 2020. 686 p.
- Национальный корпус русского языка [Электронный ресурс]. Режим доступа: https://ruscorpora.ru (дата обращения: 03.05.2021)
- Корпуса звучащей речи [Электронный ресурс]: http://spokencorpora.ru/showcorpus.py?dir=02funny (Дата обращения: 05.05.2021)